Don’t use the Bulk Loader once the Dgraph cluster is up and running. Use it to
import your existing data to a new cluster.
It is crucial to tune the Bulk Loader’s flags to get good performance. See the
next section for details.
Settings
Bulk Loader only accepts data in the RDF
N-Quad/Triple or JSON formats. Data can be
raw or compressed with gzip.
-
Reduce shards: Before running the bulk load, you need to decide how many
Alpha groups are running when the cluster starts. The number of Alpha groups
is the same number of reduce shards you set with the
--reduce_shardsflag. For example, if your cluster has 3 Alpha with 3 replicas per group, then there is 1 group and--reduce_shardsshould be set to 1. If your cluster has 6 Alphas with 3 replicas per group, then there are 2 groups and--reduce_shardsshould be set to 2. -
Map shards: The
--map_shardsoption must be set to at least what’s set for--reduce_shards. A higher number helps the Bulk Loader evenly distribute predicates between the reduce shards.
out directory by default. Here’s the bulk load
output from the preceding example:
--reduce_shards was set to 2, two sets of p directories are
generated:
- the
./out/0folder - the
./out/1folder
- Each replica of the first group (
Alpha1,Alpha2,Alpha3) should have a copy of./out/0/p - Each replica of the second group (
Alpha4,Alpha5,Alpha6) should have a copy of./out/1/p, and so on.
Each Dgraph Alpha must have a copy of the group’s
p directory output.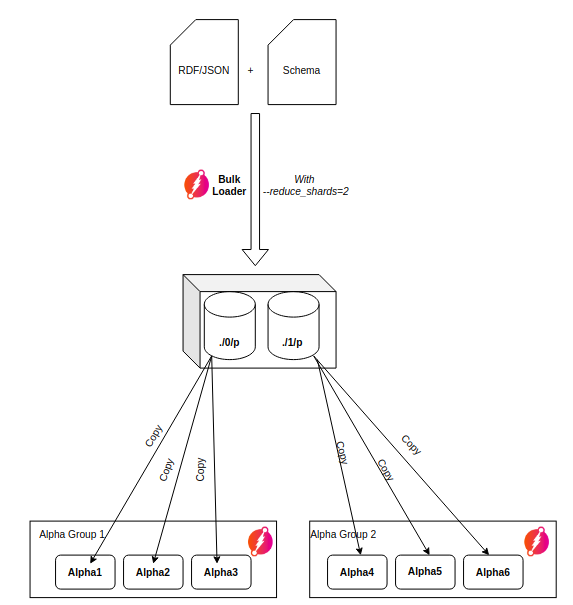
Other Bulk Loader options
You can further configure Bulk Loader using the following options:-
--schema,-s: set the location of the schema file. -
--graphql_schema,-g(optional): set the location of the GraphQL schema file. -
--badgersuperflag’scompressionoption: Configure the compression of data on disk. By default, the Snappy compression format is used, but you can also use Zstandard compression. Or, you can choose no compression to minimize CPU usage. To learn more, see Data Compression on Disk. -
--new_uids: (default: false): Assign new UIDs instead of using the existing UIDs in data files. This is useful to avoid overriding the data in a DB already in operation. -
-f,--files: Location of*.rdf(.gz)or*.json(.gz)files to load. It can load multiple files in a given path. If the path is a directory, then all files ending in.rdf,.rdf.gz,.json, and.json.gzare loaded. -
--format(optional): Specify file format (rdforjson) instead of getting it from filenames. This is useful if you need to define a strict format manually. -
--store_xids: Generate a xid edge for each node. It stores the XIDs (The identifier / Blank-nodes) in an attribute namedxidin the entity itself. -
--xidmap(default:disabled. Need a path): Store xid to uid mapping to a directory. Dgraph saves all identifiers used in the load for later use in other data import operations. The mapping is saved in the path you provide and you must indicate that same path in the next load. It is recommended to use this flag if you have full control over your identifiers (Blank-nodes). Because the identifier is mapped to a specific UID. -
--vaultsuperflag (and its options): specify the Vault server address, role id, secret id, and field that contains the encryption key required to decrypt the encrypted export.
Load from S3
To bulk load from Amazon S3, you must have either IAM or the following AWS credentials set via environment variables:| Environment Variable | Description |
|---|---|
AWS_ACCESS_KEY_ID or AWS_ACCESS_KEY | AWS access key with permissions to write to the destination bucket. |
AWS_SECRET_ACCESS_KEY or AWS_SECRET_KEY | AWS access key with permissions to write to the destination bucket. |
IAM setup
In AWS, you can accomplish this by doing the following:- Create an IAM Role with an IAM Policy that grants access to the S3 bucket.
- Depending on whether you want to grant access to an EC2 instance, or to a pod
running on EKS, you can do one of these
options:
- Instance Profile can pass the IAM Role to an EC2 Instance
- IAM Roles for Amazon EC2 to attach the IAM Role to a running EC2 Instance
- IAM roles for service accounts to associate the IAM Role to a Kubernetes Service Account.
Load from MinIO
To bulk load from MinIO, you must have the following MinIO credentials set via environment variables:| Environment Variable | Description |
|---|---|
MINIO_ACCESS_KEY | MinIO access key with permissions to write to the destination bucket. |
MINIO_SECRET_KEY | MinIO secret key with permissions to write to the destination bucket. |
How to properly bulk load
Starting from Dgraph v20.03.7, depending on your dataset size, you can follow one of the following ways to use Bulk Loader and initialize your new cluster. The following procedure is particularly relevant for Clusters that have--replicas flag greater than 1
For small datasets
In case your dataset is small (a few gigabytes) it would be convenient to start by initializing just one Alpha node and then let the snapshot be streamed among the other Alpha replicas. You can follow these steps:- Run Bulk Loader only on one Alpha server
-
Once the generated
out\0\pdirectory has been created by the Bulk Loader, copy thepdirectory (default path isout/0/p) to the Alpha volume. - Start only the first Alpha replica
-
Generate some mutations. Without mutation the Alpha will not create a
snapshot. You can run
dgraph increment -n 10000to generate some mutations on an internal counter not affecting your data. -
Wait for 1 minute to ensure that a snapshot has been taken by the first Alpha
node replica. You can confirm that a snapshot has been taken by looking for
the following message”:
-
After confirming that the snapshot has been taken, you can start the other
Alpha node replicas (number of Alpha nodes must be equal to the
--replicasflag value set in the Zero nodes). Now the Alpha node (the one started in step 2) logs similar messages:These messages indicate that all replica nodes are now using the same snapshot. Thus, all your data is correctly in sync across the cluster. Also, the other Alpha nodes print (in their logs) something similar to:
For bigger datasets
When your dataset is pretty big (larger than 10 GB) it is faster that you just copy the generatedp directory (by the Bulk Loader) among all the Alphas
nodes. You can follow these steps:
- Run Bulk Loader only on one Alpha server
- Copy (or use
rsync) the generatedout\0\pdirectory to all Alpha nodes (the servers you are using to start the Alpha nodes) - Now, start all Alpha nodes at the same time
snapshot at index value must be the same within the same Alpha group
and ReadTs must be the same value within and among all the Alpha groups.
Enterprise features
Multi-tenancy
By default, Bulk Loader preserves the namespace in the data and schema files. If there’s no namespace information available, it loads the data into the default namespace. Using the--force-namespace flag, you can load all the data into a specific
namespace. In that case, the namespace information from the data and schema
files are ignored.
For example, to force the bulk data loading into namespace 123:
Encryption at rest
Even before the Dgraph cluster starts, we can load data using Bulk Loader with the encryption feature turned on. Later we can point the generatedp directory
to a new Alpha server.
Here’s an example to run Bulk Loader with a key used to write encrypted data:
vault_* options can be used to
decrypt the encrypted export.
Encrypting imports
The Bulk Loader’s--encryption key-file=value option was previously used to
encrypt the output p directory. This same option is also used to decrypt the
encrypted export data and schema files.
Another option, --encrypted, indicates whether the input rdf/json data and
schema files are encrypted or not. With this switch, we support the use case of
migrating data from unencrypted exports to encrypted import.
So, with the preceding two options there are four cases:
-
--encrypted=trueand noencryption key-file=value. Error: if the input is encrypted, a key file must be provided. -
--encrypted=trueandencryption key-file=path-to-key. Input is encrypted and outputpdir is encrypted as well. -
--encrypted=falseand noencryption key-file=value. Input isn’t encrypted and the outputpdir is also not encrypted. -
--encrypted=falseandencryption key-file=path-to-key. Input isn’t encrypted but the output is encrypted. (This is the migration use case mentioned previously).
vault_* options can be used instead
of the --encryption key-file=value option to achieve the same effect except
that the keys are sitting in a Vault server.
You can also use Bulk Loader, to turn off encryption. This generates a new
unencrypted p that’s used by the Alpha process. In this, case you need to pass
--encryption key-file, --encrypted and --encrypted_out flags.
--encrypted=true as the exported
data has been taken from an encrypted Dgraph cluster and we’re also specifying
the flag --encrypted_out=false to specify that we want the p directory (that
is generated by the Bulk Loader process) to be unencrypted.
Tuning & monitoring
Performance tuning
We highly recommend turning off swap
space when
running Bulk Loader. It is better to fix the parameters to decrease memory
usage, than to have swapping grind the loader down to a halt.
dgraph bulk --help. In
particular, you should tune the flags so that Bulk Loader doesn’t use more
memory than is available as RAM. If it starts swapping, it becomes incredibly
slow.
In the map phase, tweaking the following flags can reduce memory usage:
-
The
--num_go_routinesflag controls the number of worker threads. Lowering reduces memory consumption. -
The
--mapoutput_mbflag controls the size of the map output files. Lowering reduces memory consumption.
.rdf.gz files (e.g. 256MB each). This
has a negligible impact on memory usage.
The reduce phase is less memory heavy than the map phase, although can still
use a lot. Some flags may be increased to improve performance, but only if you
have large amounts of RAM:
-
The
--reduce_shardsflag controls the number of resultant Dgraph Alpha instances. Increasing this increases memory consumption, but in exchange allows for higher CPU utilization. -
The
--map_shardsflag controls the number of separate map output shards. Increasing this increases memory consumption but balances the resultant Dgraph Alpha instances more evenly.